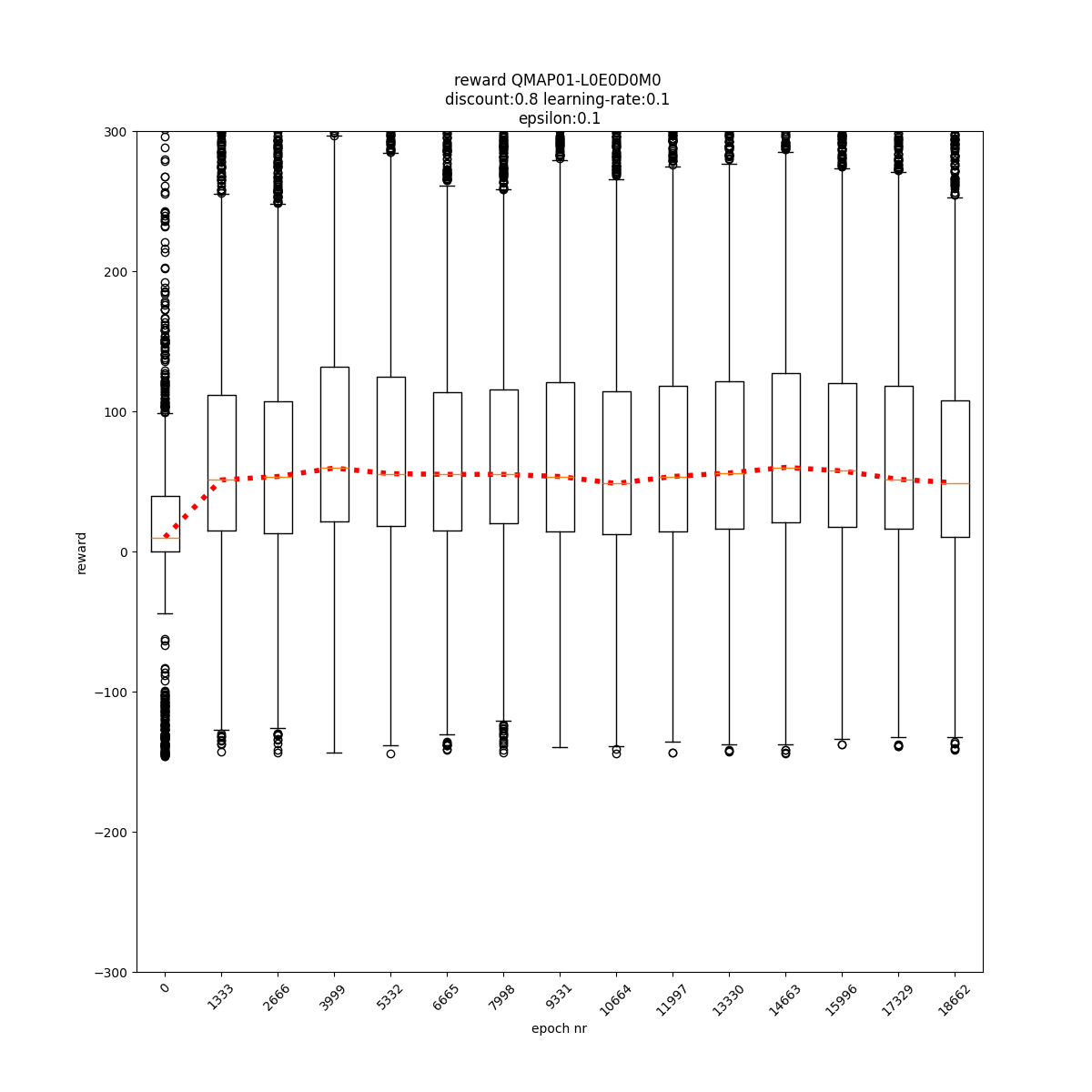
L0 E0 D0 M0
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
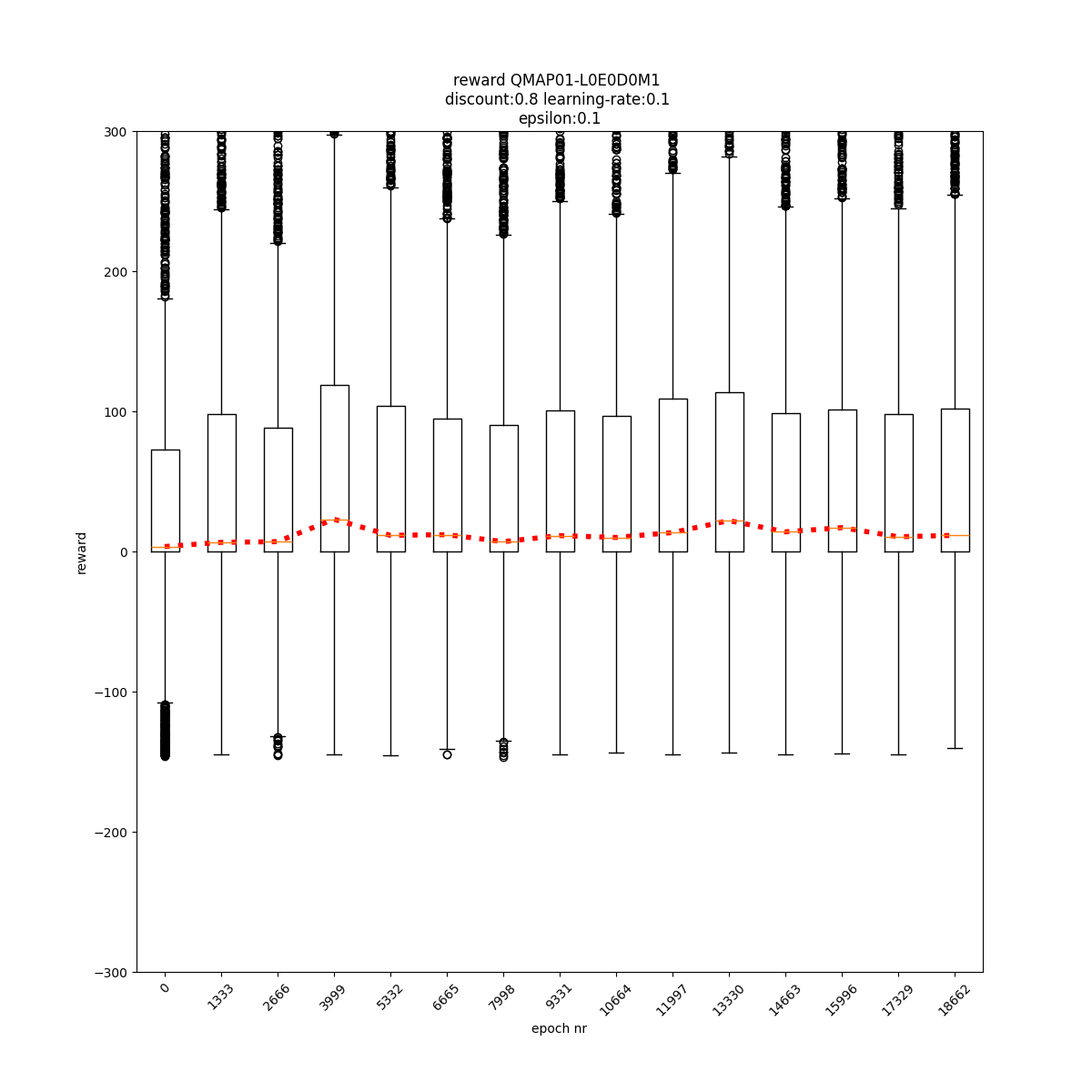
L0 E0 D0 M1
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
L0 E0 D0 M2
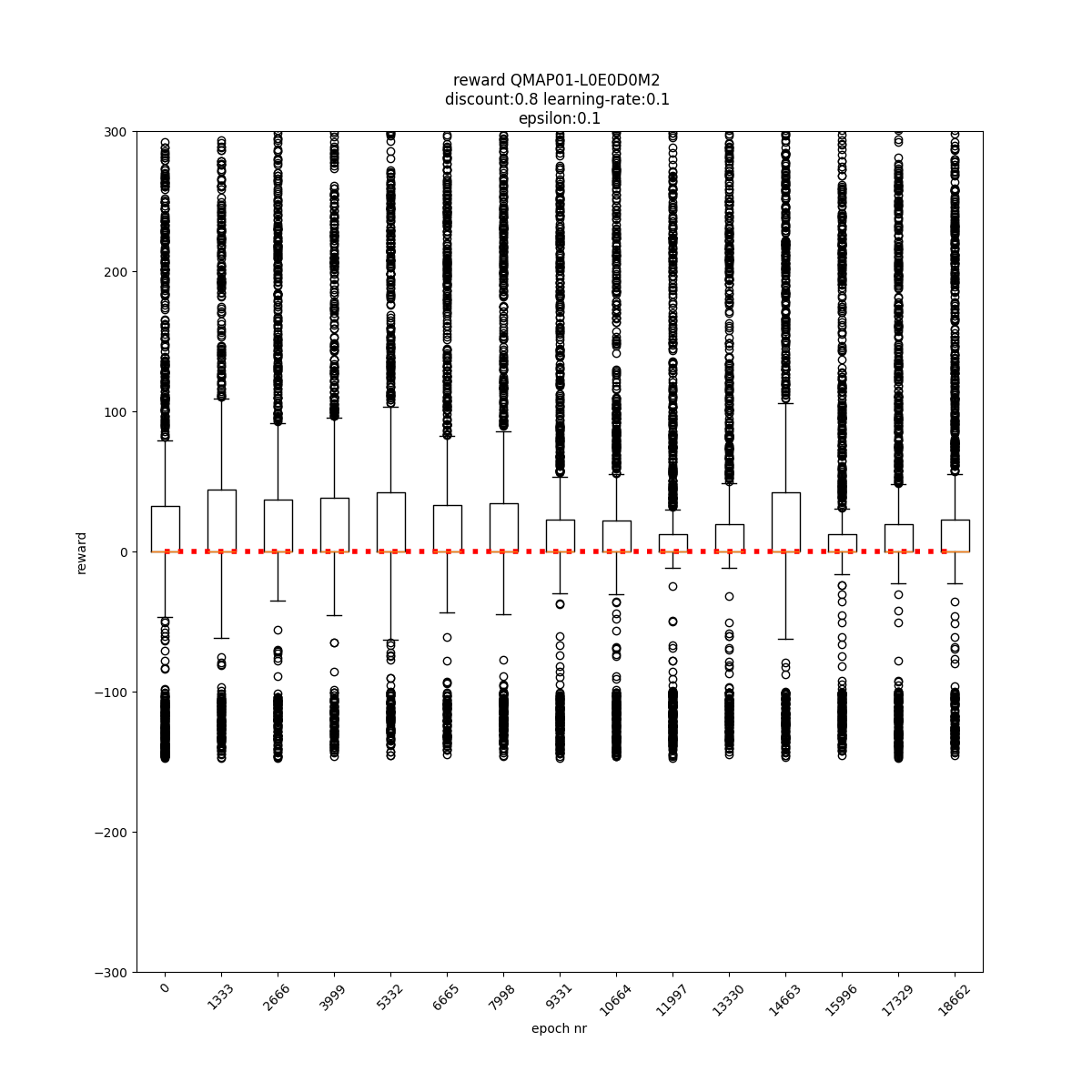
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
L0 E0 D0 M3
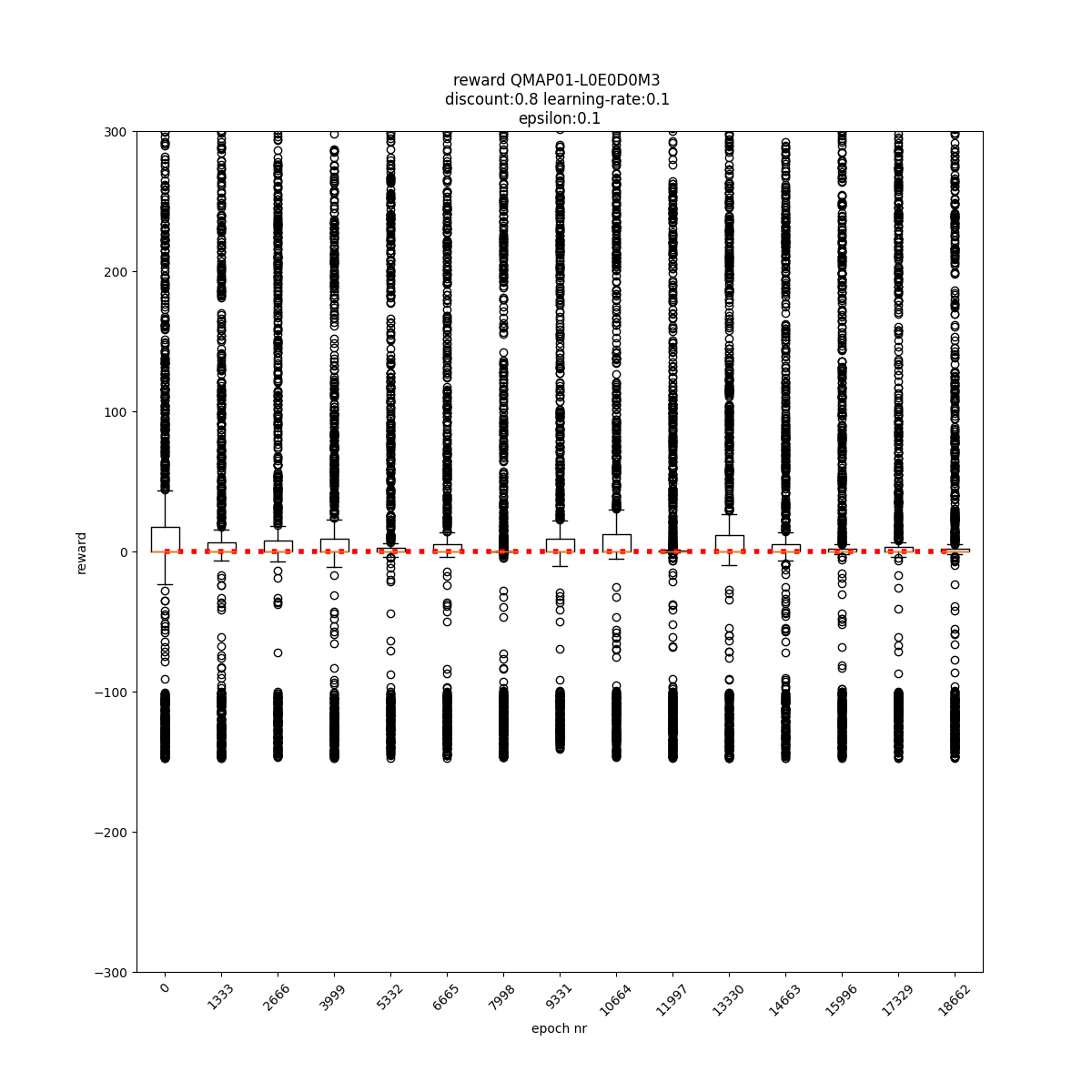
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
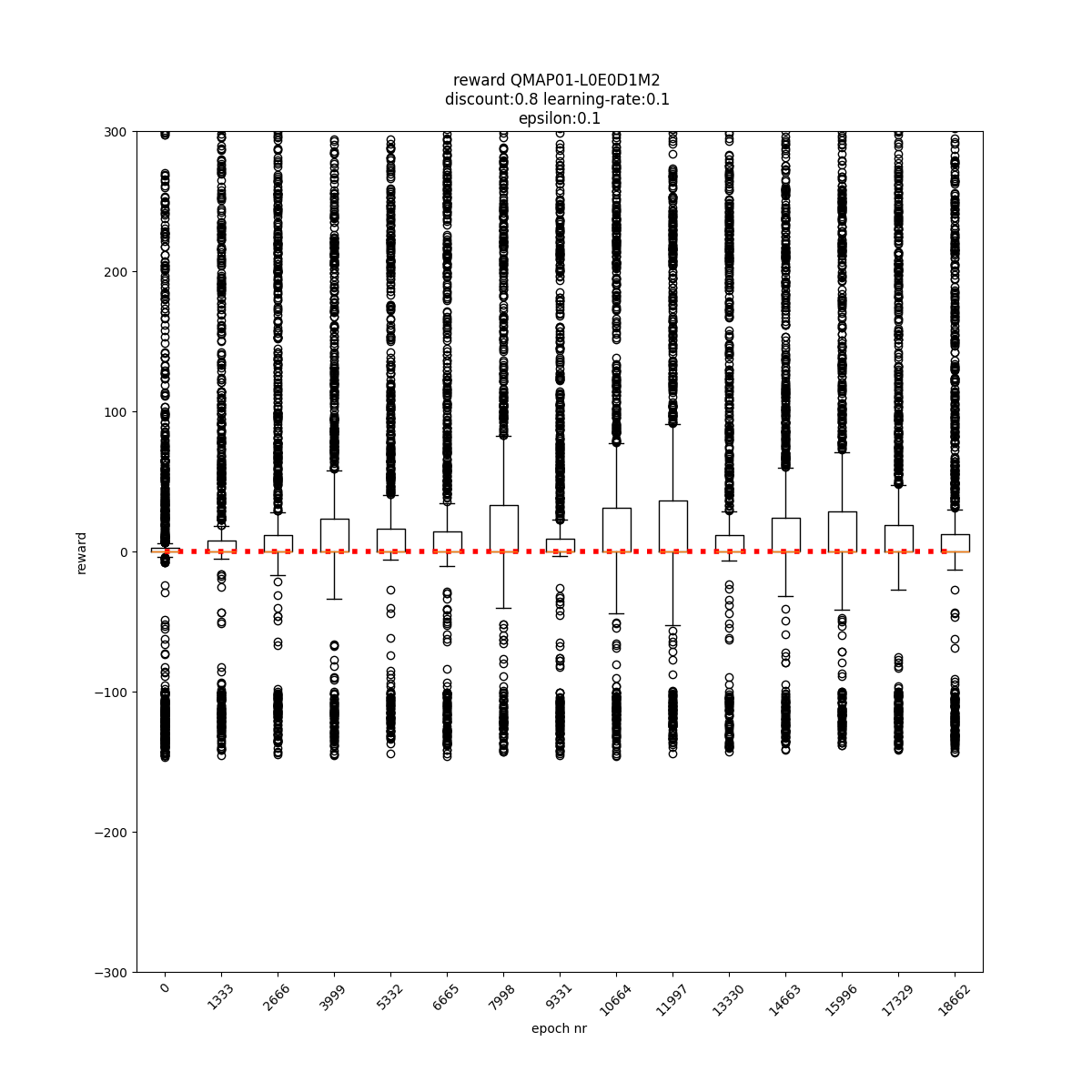
L0 E0 D1 M0
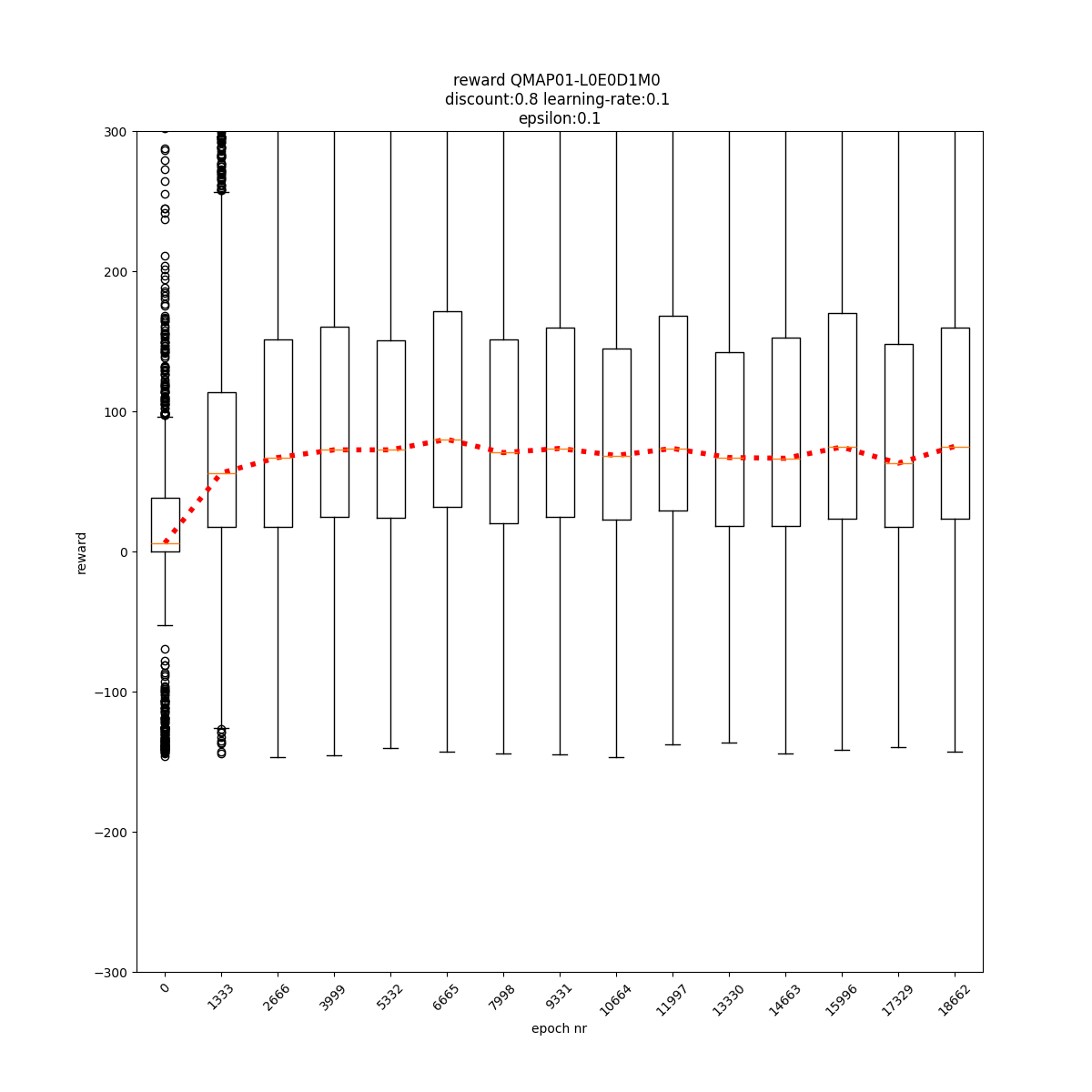
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
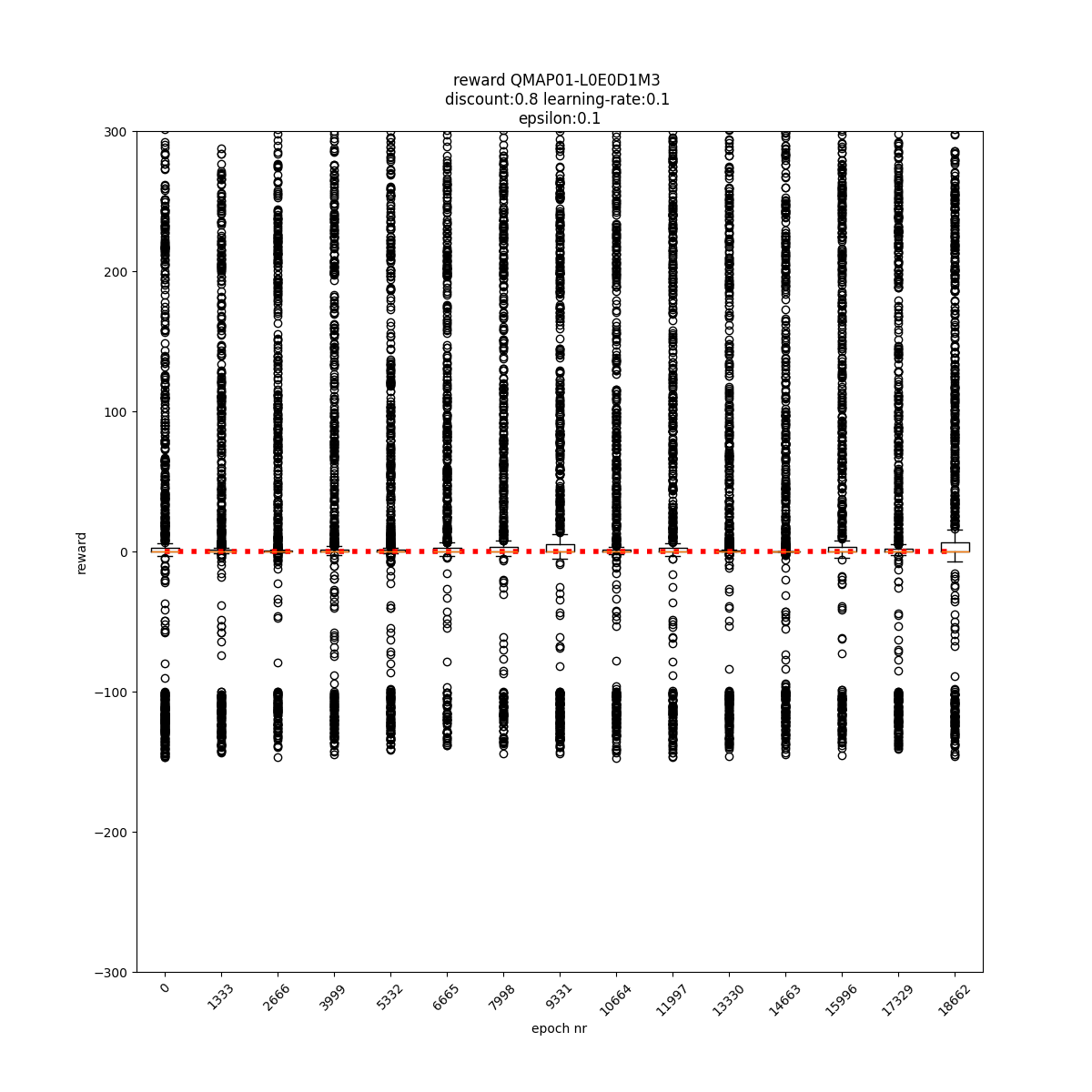
L0 E0 D1 M1
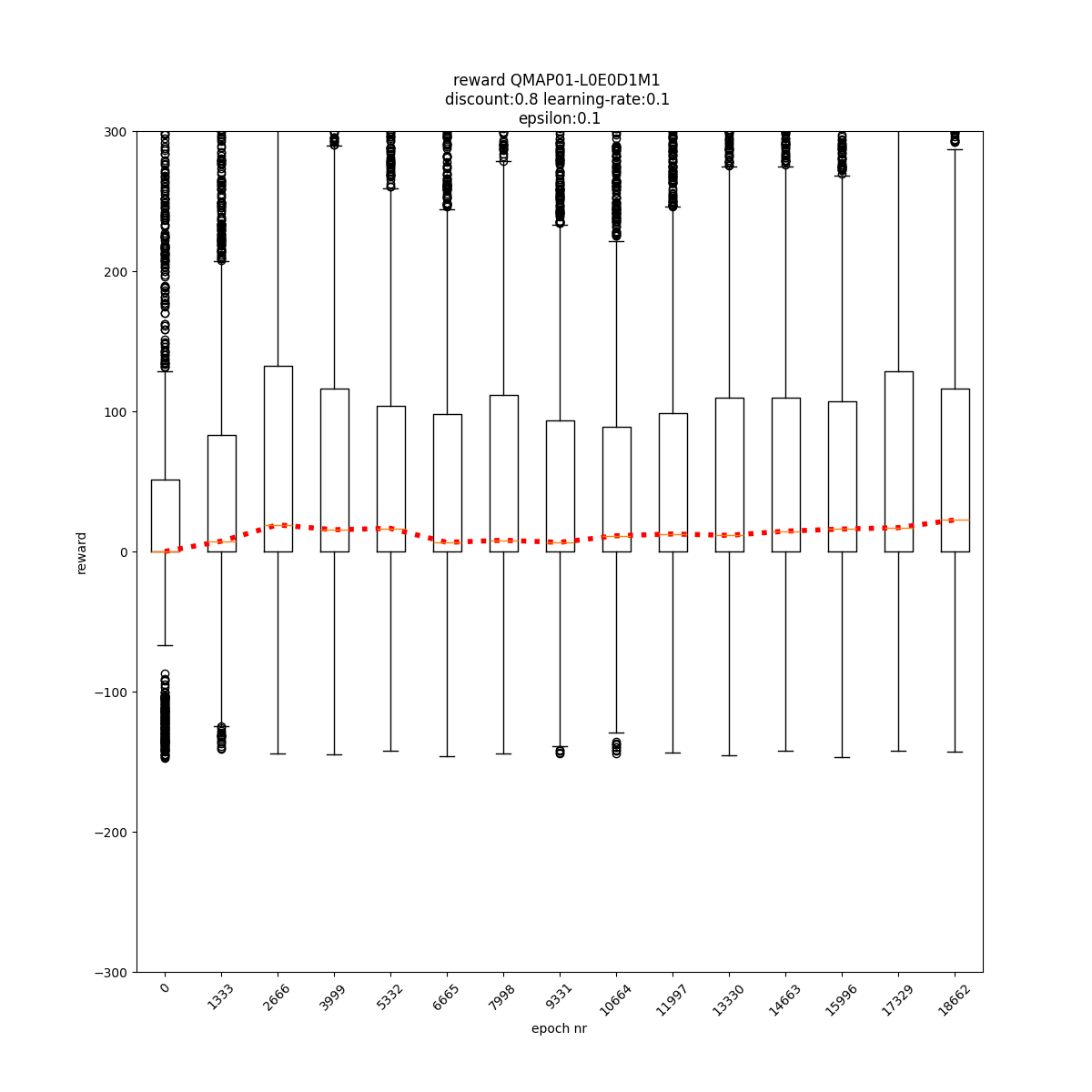
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11
q-values
video 0 video 1 video 2 video 3
video 4 video 5 video 6 video 7
video 8 video 9 video 10 video 11